
How to Build a RAG for Cryptocurrency News
Learn the steps to make a chatbot powered by AI with Python completly for free with Chromadb, Langchain and LLMs.

The crypto space is constantly evolving, with market trends shifting rapidly in response to geopolitical events, protocol updates, social media buzz, significant cryptocurrency movements, and influential figures, among other factors.
As a result, crypto articles can become outdated quickly. What’s relevant one week may not be the next. Therefore, writers must continuously monitor trends and produce fresh content at a rate that is hard to see in other technological fields.
This constant stream of cryptocurrency, blockchain, and web3 news serves as a valuable resource for those looking to inform their investment strategies, develop apps around trending topics, analyze market sentiment, or simply stay up-to-date on the latest ecosystem advancements.
We can get the latest news with web scrapers, but what about fetching the information that we’re looking for without spending time reading through several articles or making extensive Google searches?
To address this challenge, I created a Retrieval-Augmented Generation (RAG) system specifically designed for crypto news. This system enables users to query topics related to cryptocurrencies, blockchain, and web3, and receive the most up-to-date information on those subjects.
For example, if you ask ChatGPT to explain Decentralized Finance (DeFi), it can provide a detailed and comprehensive answer. However, if you ask about the latest Ethereum price predictions, the chat interface may need to search the web, and its response will likely be limited.
In this piece, I will guide you through the steps I took to build CryptoRAG, a chatbot tailored to get the latest information about cryptocurrencies, blockchain and web3.
We’ll start by exploring the fundamentals of RAG systems and the specific architecture I implemented. Next, we’ll cover how to upload the data to the Chroma database by creating Langchain documents. In addition, we’ll look at the query function, the prompt template, and two different ways of using Llama3.3 in the pipeline. Finally, we’ll bring everything together by creating a user interface to enable question-answering capabilities.
Hands-on with my CryptoRAG architecture
Large Language Models (LLMs) are trained on huge volumes of publicly available data on the internet, and use countless parameters to originate outputs that can answer your questions, create original content, or simply communicate with you. However, just like human beings, these models don’t have all the information in the world, and certainly not the latest one.
Retrieval-Augmented Generation (RAG) fixes this by integrating external data from a specific domain, document, or other sources with a Large Language Model (LLM). This hybrid approach enables the model to produce outputs that are tailored to a particular field or industry.
The RAG process is split into 3 main modules
Retrieval Module: This module fetches and ranks relevant data within a vector database based on a given input. During this process, the input query is analyzed, and the system searches through indexed data to retrieve information that aligns with the query, prioritizing relevance.
Augmentation Module: This second module plays a crucial role in enhancing the performance of the RAG system. Its function is to take the top-ranked data retrieved from the Retrieval Module and seamlessly integrate it into the prompt that feeds the Large Language Model (LLM). By adding the relevant external data to the prompt, the Augmentation Module provides the LLM with additional context and information, enabling more accurate, informative, and relevant responses.
Generation Module: This module generates a response by combining its language capabilities with newly retrieved external data, which is incorporated in the prompt template for the LLM. The result is a response based on the external data but cleaned and explained like the LLM would do for it’s default trained data. Depending on the prompt template, the output can show sources and other metadata features.
Based on the above steps, my CryptoRAG architecture ended up like this:
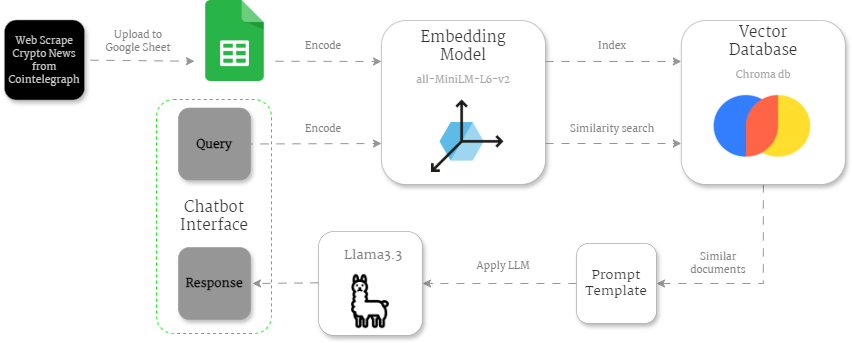
Outside the RAG modules, there’s the Web Scraping script I run daily to get the latest cryptocurrency news using my Cointelegraph Scraper on Apify.
Since I don’t need a big storage solution, a simple Google Sheet serves to retain the crypto news data temporarily.
Then I used a script to extract the data from the Google Sheet and start the encoding process, where I used Langchain to split the data into chunks and add metadata. These chunks are then vectorized using a well-known embedding model from Hugging Face: sentence-transformers/all-MiniLM-L6-v2. At this point, we are already in the Retrieval Module.
Once the chunks are vectorized, they are stored in the Chroma vector database. I chose Chroma because it is a completely open-source solution with no associated costs, making it an accessible and budget-friendly option.
When an input is provided to the RAG system, it is also encoded using the same embedding model, and the most relevant chunks of information are fetched from the Chroma database using similarity search. In other words, it compares vectors of information, and the closest numbers match the information that is most related to the input.
Now we enter the Augmentation Module, where the most similar documents are used to create a prompt template to feed into the LLM model (Llama 3.3). Later, we’ll explore how to design an effective prompt and use the model, whether for free or via paid APIs.
Once the prompt template is applied to the LLM, it generates a response to the initial query, completing the Q&A process. The input and outputs are connected through a simple chat interface with some suggestions for those starting to use the app.
Access the data and create documents with Langchain
As mentioned previously, the scraper uploads the data to a Google Sheet. To access it, some configurations in the Google Cloud Platform must be done beforehand, such as creating a service account and generating credentials. You can learn more about it here.
Once done, we can use gspread Python library to access the Google Sheet and extract the information as a Pandas dataframe.
import pandas as pd
import gspread
from google.oauth2.service_account import Credentials
class GoogleAccess:
""" Class containing the Google interaction functions """
@staticmethod
def google_authentication(credentials) -> object:
""" This function gives authentication to the Google Account.
Scopes defines the permissions to Google Sheets and Google Drive.
Than, using gspread, it authorizes the authentication and
opens the worksheet to work with.
"""
# Authenticate with Google Sheets using the JSON key file
scope = ['https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive']
creds = Credentials.from_service_account_file(
credentials, scopes=scope)
client = gspread.authorize(creds)
return client
@staticmethod
def read_from_sheet(client, sheet_id) -> pd.DataFrame:
""" This function reads the data from the Google Sheet. """
# Open the Google Sheet by id
sheet = client.open_by_key(sheet_id)
# Access the worksheet name
ws = sheet.worksheet('main')
# Create a dataframe
df = pd.DataFrame(data=ws.get_all_records())
return dfThe credentials are stored in a JSON file that contains the service account information. To create Langchain documents, we just need to use the credentials file along with the Google Sheet ID as inputs in this function:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
def create_documents(credentials_google, google_sheet_id):
""" This function splits the articles in chunks
from a dataset obtained by reading a google sheet.
And creates documents with each chunk.
"""
# Create client
client = GoogleAccess.google_authentication(credentials_google)
df = GoogleAccess.read_from_sheet(client, google_sheet_id)
df['id'] = df['id'].astype('str')
# Initialize the text splitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=5000,
chunk_overlap=0)
# Create a list of LangChain documents
documents = []
for _, row in df.iterrows():
content_chunks = splitter.split_text(row['content'])
for i, chunk in enumerate(content_chunks):
documents.append(Document(
page_content=chunk,
metadata={
"category": row['category'],
"link": row['link']
},
id=f"{row['id']}{i}"
))
return documentsFor each article (row in the dataframe), I divide it into chunks of 5,000 characters. I opted for larger chunks because smaller ones seemed to negatively impact my RAG’s performance, resulting in poor-quality information about the articles. I also included the link in the metadata to embed the sources of information directly into the final chatbot interface.
Upload the encoded documents to the Chroma vector database
The previous functions allowed me to create the Langchain documents, but I still needed to vectorize and upload them to the vector database. This is achieved in the following script:
import os
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from src.preprocess import create_documents
from langchain_chroma import Chroma
load_dotenv('keys.env')
def update_chromadb():
"""Update ChromaDB with new documents by deleting existing
collection and creating a new one."""
try:
# Create temporary directory for new database
temp_dir = "chroma_temp"
os.makedirs(temp_dir, exist_ok=True)
# Initialize Hugging Face embeddings
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2")
# Create new documents
documents = create_documents(
'credentials.json', os.getenv("SHEET_ID"))
# Create new database in temporary location
Chroma.from_documents(
documents=documents,
collection_name="cointelegraph",
embedding=embedding_model,
persist_directory=temp_dir
)
# If successful, replace old database with new one
if os.path.exists("chroma"):
shutil.rmtree("chroma")
shutil.move(temp_dir, "chroma")
logger.info(
"Successfully refreshed ChromaDB collection with new documents")
return True
except Exception as e:
logger.error("Error updating ChromaDB: %s", str(e))
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
raiseThe chroma object, integrated with Langchain, is instantiated using the .from_documents() function to upload the previously created documents and simultaneously embed them using the sentence-transformers/all-MiniLM-L6-v2 model from Hugging Face.
The data is stored in the cointelegraph collection, which works like a table in SQL databases. During the process, the data is temporarily stored in a folder named chroma_temp. If the documents are successfully updated, they replace the existing data in the main database folder, chroma.
At the moment of launching the application, the following function is triggered to get the Chroma db object without making any changes in the database:
def initialize_chatbot():
"""Initialize ChromaDB and embeddings."""
global db, embedding_model, last_update
try:
# Initialize Hugging Face embeddings
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2")
# Load existing database
db = Chroma(
collection_name="cointelegraph",
embedding_function=embedding_model,
persist_directory="chroma"
)
if not last_update:
last_update = datetime.now()
logger.info("Successfully loaded ChromaDB collection")
except Exception as e:
logger.error("Error initializing ChromaDB: %s", str(e))
raiseThis db object will be used to query the vector database and obtain a response, which we will see in the next chapter.
Query the RAG system and get a detailed output
This is the part where we finally use the LLM, and for that, I tried two approaches. The first one is free to use with Ollama. But if you lack a GPU, chances are that the model will take too much computational time. The second approach is using OpenRouter models and the OpenAI Python library.
Use an LLM for free in your RAG system
Let’s start by exploring the free method using Ollama. You first need to install it via curl in your WSL or Linux machine with this command:
curl -fsSL https://ollama.com/install.sh | shNext, run the following command to start Ollama:
ollama serveFetch the Ollama model you want to use:
ollama run llama3.3The model Llama3.3 is huge! So either you have enough storage (and a GPU) to run it, or I recommend you look for lightweight Ollama model alternatives, such as mistral.
Now guess what? There’s also a Langchain python package for Ollama, so let’s install it:
pip install langchain-ollamaWith this configuration, our query function would look like this:
from langchain_core.prompts import PromptTemplate
import os
from langchain_ollama.llms import OllamaLLM
def query_rag(query_text, db, prompt, model_name):
"""
Query a Retrieval-Augmented Generation (RAG) system using Chroma database,
and format the response with links and categories.
"""
# Retrieving the context from the DB using similarity search
results = db.similarity_search_with_relevance_scores(query_text, k=3)
# Check if there are any matching results or if
# the relevance score is too low
if len(results) == 0 or results[0][1] < 0.2:
return (
"No relevant information found. Try to ask something "
"related to crypto, blockchain and web3.")
else:
# Combine context from matching documents
context_text = "\n\n - -\n\n".join(
[doc.page_content for doc, _score in results]
)
# Extract categories and links from metadata
categories = ", ".join(
{doc.metadata.get("category", "Unknown") for doc, _ in results})
links = ", ".join(
{doc.metadata.get("link", "N/A") for doc, _ in results})
# Create and format the prompt
template = PromptTemplate(
input_variables=["context", "question", "categories", "links"],
template=prompt,
)
prompt = template.format(
context=context_text,
question=query_text,
categories=categories,
links=links
)
# Use the language model to generate a response
model = OllamaLLM(
model=model_name, cache=False, verbose=True, num_ctx=500)
response_text = model.invoke(prompt)
# Format and return response including generated text and sources
formatted_response = f"{response_text}\nSources: {links}"
return formatted_responseNote that the model_name input you see in the script above, should be a string with the name of the model you are running in Ollama, for instance llama3.3.
Use OpenRouter models with OpenAI
If you don’t have a GPU, like me, the best option is to use a paid service. I prefer OpenRouter because it allows me to purchase credits with crypto and works seamlessly with the OpenAI Python package:
pip install openaiOnce the package is installed, you need to generate a token in your OpenRouter account and change the query function to this instead:
from langchain_core.prompts import PromptTemplate
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv("keys.env")
def query_rag(query_text, db, prompt):
"""
Query a Retrieval-Augmented Generation (RAG) system using Chroma database,
and format the response with links and categories.
"""
# Retrieving the context from the DB using similarity search
results = db.similarity_search_with_relevance_scores(query_text, k=3)
# Check if there are any matching results or if
# the relevance score is too low
if len(results) == 0 or results[0][1] < 0.2:
return (
"No relevant information found. Try to ask something "
"related to crypto, blockchain and web3.")
else:
# Combine context from matching documents
context_text = "\n\n - -\n\n".join(
[doc.page_content for doc, _score in results]
)
# Extract categories and links from metadata
categories = ", ".join(
{doc.metadata.get("category", "Unknown") for doc, _ in results})
links = ", ".join(
{doc.metadata.get("link", "N/A") for doc, _ in results})
# Create and format the prompt
template = PromptTemplate(
input_variables=["context", "question", "categories", "links"],
template=prompt,
)
prompt = template.format(
context=context_text,
question=query_text,
categories=categories,
links=links
)
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("API_KEY"),
)
completion = client.chat.completions.create(
model="meta-llama/llama-3.3-70b-instruct",
messages=[
{
"role": "user",
"content": prompt
}
]
)
response_text = completion.choices[0].message.content
formatted_response = f"{response_text}\nSources: {links}"
return formatted_responseThis approach produces much faster results, than the free one, but also comes with a cost. For instance, using 2,495 tokens in the prompt, I paid $0.000433.
Build the right prompt template
As you have seen in the previous scripts, the query_rag() function takes a prompt as input. There are many ways of building it, mine took this direction:
PROMPT_TEMPLATE_1 = """
You are an expert assistant. Using the provided context from the
database, answer the question in detail. Write your response without
referencing articles, documents, or sources explicitly. Never start or
mention the following: "In the piece", "In the article" and so on in the
response. Provide clear and concise answers that are helpful and
relevant to the question.
Context:
{context}
Question:
{question}
Answer:
- Detailed response:
- Relevant categories: {categories}
- Links to explore further: {links}
"""I had to explicitly state that I didn’t want the answer to begin by mentioning articles, as that happened a few times. Additionally, I wanted to integrate the context, the question, and the metadata information in the final output.
To create a template prompt for the model, I had to install langchain_core:
pip install langchain-coreOnce done, I use the PromptTemplate instance to create the final prompt object that you can see in the previous scripts (both paid and free versions).
Build the chat interface with Flask and Cursor IDE
I’ve decided to use Python for the backend because it eases the process of connecting to Langchain, LLM packages and Chroma database. Therefore, I used the Flask framework to run the server.
In addition, I used the capabilities of Cursor composer to help me build a robust app.py script that runs daily, because I need the latest information to be uploaded to the Chroma database while the application runs.
The final main function looks like this:
""""Flask web application for Web3 & Cryptocurrency Expert Chatbot."""
# pylint: disable=W0718
import logging
import sys
import os
from langchain_chroma import Chroma
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from flask import Flask, request, jsonify, render_template, send_from_directory
from flask_cors import CORS
from src.pipeline import query_rag
from src.prompts import PROMPT_TEMPLATE_1
from flask_apscheduler import APScheduler
from datetime import datetime
from src.db_handler import update_chromadb
class Config:
SCHEDULER_API_ENABLED = True
scheduler = APScheduler()
# Configure logging with more detailed format
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler('app.log')
]
)
logger = logging.getLogger(__name__)
# Initialize Flask app
app = Flask(__name__, static_folder='static', static_url_path='/static')
app.config.from_object(Config())
CORS(app)
# Initialize global variables for database and embedding model
db = None
embedding_model = None
last_update = None
def update_db_task():
"""Background task to update the database"""
global db, last_update
try:
logger.info("Starting scheduled database update...")
# Update the database
update_chromadb()
# Reinitialize the database connection
initialize_chatbot()
last_update = datetime.now()
logger.info("Scheduled database update completed successfully")
except Exception as e:
logger.error(f"Error in scheduled database update: {str(e)}")
@app.route('/')
def home():
"""Render the chat interface."""
try:
return render_template('index.html')
except Exception as e:
logger.error("Error serving home page: %s", str(e))
return "Internal server error", 500
@app.route('/chat', methods=['POST'])
def chat():
"""Handle chat messages using RAG system."""
try:
if db is None or embedding_model is None:
logger.error("Chatbot components not properly initialized")
return jsonify({'error': 'Chatbot not initialized properly'}), 503
data = request.get_json()
if not data or 'message' not in data:
logger.warning("Invalid request: missing message")
return jsonify({'error': 'No message provided'}), 400
user_message = data['message'].strip()
logger.info("Processing chat message: %s...", user_message[:50])
# Use RAG system to generate response
formatted_response= query_rag(
user_message, db, PROMPT_TEMPLATE_1)
logger.info("Successfully generated response")
return jsonify({
'response': formatted_response,
})
except Exception as e:
logger.error("Error processing chat message: %s", str(e))
return jsonify(
{'error': 'An error occurred while processing your request'}), 500
if __name__ == '__main__':
try:
# Clear log files at startup
clear_log_files()
# Initialize scheduler
scheduler.init_app(app)
# Schedule database updates every 10 minutes
scheduler.add_job(
id='update_db',
func=update_db_task,
trigger='interval',
days=1,
next_run_time=datetime.now() # Run once immediately
)
scheduler.start()
# Initialize chatbot components
logger.info("Starting application initialization...")
initialize_chatbot()
logger.info(
"Chatbot initialization and "
"scheduler setup completed successfully")
# Start Flask server
logger.info("Starting Flask server on port 5000...")
app.run(host='0.0.0.0', port=5000, debug=False, use_reloader=False)
except Exception as e:
logger.error("Critical server error: %s", str(e))
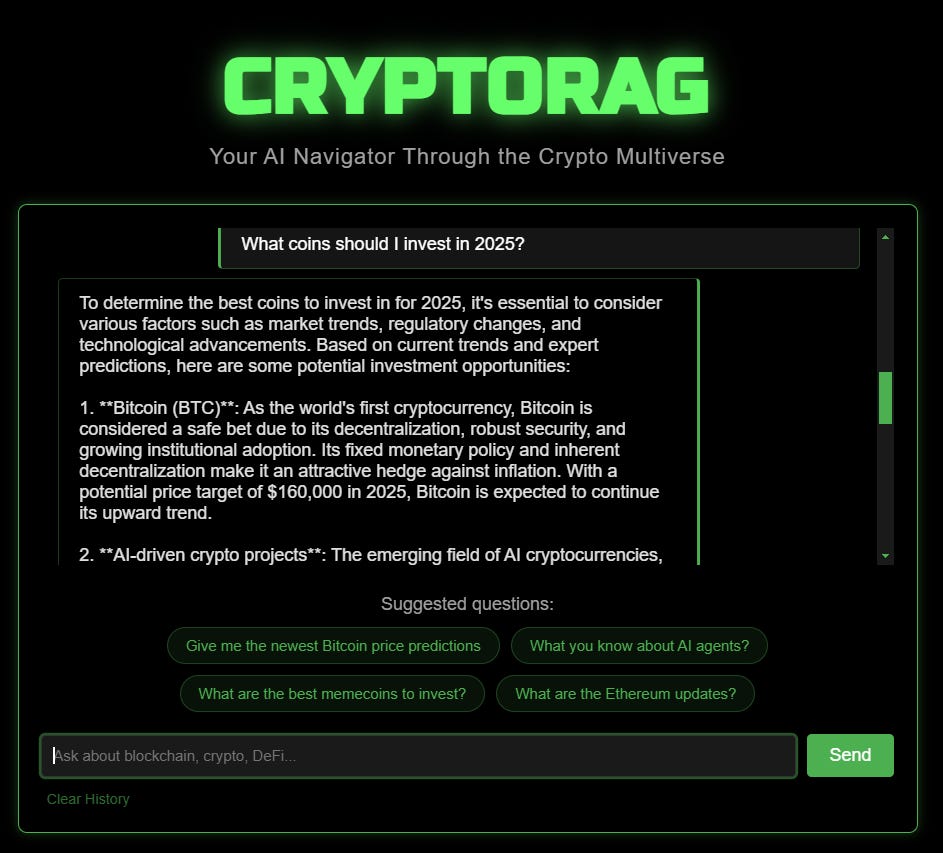
sys.exit(1)For the front-end, I mostly relied on Cursor composer to build the interface, and then I adjusted the HTML elements myself. However, it’s clear that you don’t need to be a front-end developer to create a ready-to-go application nowadays. Here’s how the app looks like:
For deployment, I’m currently using Replit. I simply connected my GitHub account, made a few configurations, and clicked the deploy button.
Need help with automation, AI, or data science? Let’s talk.
Conclusion
Building a RAG system doesn’t take much time today with the help of AI and the right tools. With so many frameworks and options available, it can be overwhelming to know where to start.
That’s why, even though it’s not the most user-friendly, I prefer sticking with Langchain. I need to install several libraries during the process, but at least I know they’re compatible and won’t break the pipeline. For vector databases, free and open-source solutions like Chroma DB work well, and when it comes to LLMs, just choose the one that fits your needs.
Concerning programming, there’s no going back, you either use Copilot, Cursor, or another AI-powered IDE, or your productivity will lag behind both developers and non-developers. It’s amazing to see how quickly we can build applications now!
I hope this tutorial helps you get started with your own RAG system and saves you time searching for the right tools. And remember, try CryptoRAG and leave your honest feedback/support if you find the chatbot useful!