
5 Tips to Turn You Into a Pro Web Scraper With Playwright
AI tools and vibe coding make web scraping easier than ever, but without these strategies, most sites will still block you.

Web scraping seems to have taken the lead in internet traffic. Following the 2025 Imperva Bad Bot Report, 51% of global web traffic is now automated, surpassing humans.
A key element in this is Artificial Intelligence (AI), which requires vast amounts of data for model training and therefore relies on massive crawlers running nonstop. At the same time, AI has also made web scraping more accessible, allowing non-developers to collect data through vibe coding and seamless APIs.
According to a report by Market Research Future, the web scraper software market was valued $1.01 billion in 2024. In 2025, the Mordor Intelligence report shows that the same market is now valued at $1.03 billion, a steady 1.98% increase in just one year. The same report projects that the web scraping market will reach $2 billion by 2030, nearly 98% growth in just six years.
While web scraping is more accessible with the integration of AI, many websites have also shielded themselves against massive bot requests. Making the job difficult for many APIs and web scrapers powered by vibe coding scripts.
In this piece, I’m sharing with you 5 tips that Large Language Models (LLMs) don’t tell you to build a robust web scraper that can outperform 90% of the websites with only one tool: Playwright.
First steps with Playwright
At the time I’m writing, I have over 20 Apify actors running, all built using Playwright.
Before, I used to web scrape with Selenium, Beautiful Soup, and Scrapy, but I’ve realized that I can have successful bots only using Playwright, so why complicate things?
Playwright is a headless browser considered to be faster than its competitors and with better support for modern websites. Documentation is easy to follow and supports multiple languages.

To install Playwright, you need the following pip command:
pip install playwrightTo install the supported browsers, use this command in your terminal:
playwright installNow, the basic component of Playwright is often called page and it is instantiated this way:
from playwright.async_api import async_playwright
async with async_playwright() as pw:
# creates an instance of the Chromium browser and launches it
browser = await pw.chromium.launch(headless=False)
# creates a new browser page (tab) within the browser instance
page = await browser.new_page()I will not cover all of Playwright’s functions in this piece, but I will highlight the ones I use in most of my crawlers and have proven to be indispensable:
# Go to page and wait to render full content: images, APIs and more
await page.goto(”some_url”, wait_until=”networkidle”)
# Go to page and wait only for DOM structure (initial HTML). Much faster.
await page.goto(”some_url”, wait_until=”domcontentloaded”)
# Create some timing between actions
await page.wait_for_timeout(3000)
# Get text content only
await page.locator(”a”).text_content()
# Get an attribute
await page.locator(”a”).get_attribute(”href”)
# Get all elements with the same class
elements = await page.locator(”a.font-big”).all()
# Click the first element
await page.locator(”a.font-big”).first.click()
# Click the last element
await page.locator(”a.font-big”).last.click()
# Click element by index
await page.locator(”a.font-big”).nth(3).click()In addition to these examples, it is also useful to use page.get_by_role(), page.get_by_title(), page.get_by_label(), and so on, whenever you can. This is usually more straightforward than using the page.locator().
For more about Playwright’s functions, visit the well-structured official documentation.
Now we will have a look at the 5 tips to improve your web scraping skills while integrating Playwright. They aim at answering the following questions:
How to increase the stealth performance?
How to intercept the website’s HTTP response?
How to handle infinite scroll websites?
How to target HTML elements accurately?
How to make proper proxy rotation?
Let’s get started!
1 - How to increase the stealth performance?
If you’re familiar with Playwright, you’ve probably heard of playwright_stealth.
While it can work for some websites, it is definitely an outdated solution to improve your stealth performance.
The alternative: Camoufox.
This open-source anti-detect browser can be integrated with the Playwright API. It works by providing Camoufox with detailed device characteristics, including the operating system, device information, navigator properties, headers, screen size, and more.
To install Camoufox, use this pip command:
pip install -U camoufoxYour playwright’s page object can be instantiated in the following way:
from camoufox import AsyncCamoufox
async with AsyncCamoufox(
os=”macos”,
humanize=True, # Enable humanized cursor movement
headless=False, # Keep visible for debugging
window=(1280, 720), # Set window size
) as browser:
page = await browser.new_page()Using this browser won’t solve all your issues. You may still get blocked by websites protected by Datadome, but it is significantly better than using Playwright only.
You can also add proxies, tweak the parameters, and add BrowserForge to see if the stealth is improved.
2 - How to intercept the website’s HTTP response?
Many developers who engage in web scraping tend to strictly extract and parse the HTML content. While this solution works, it may not be the fastest way to crawl data, and you may miss important metadata and features.
Many modern websites don’t load all their data in the initial HTML. Instead, they fetch data dynamically from APIs (such as JSON and GraphQL) after the page loads.
Therefore, before tackling the HTML content, check if the website has an API response. This can be triggered by simply loading the page, clicking on buttons, or scrolling the page.
Let’s take the Hackernoon website as an example.
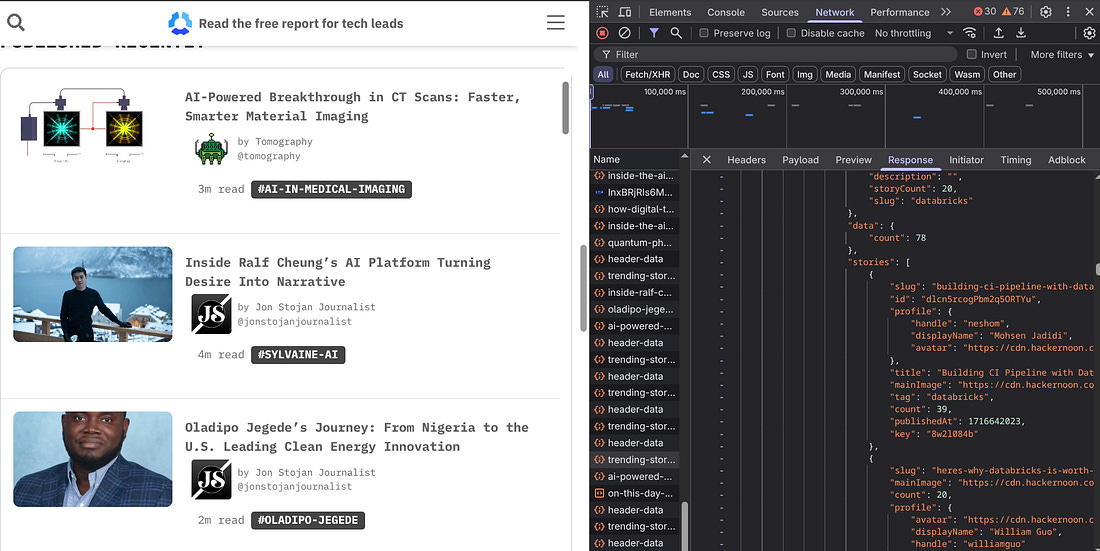
In this case, there’s a JSON API response for each article that contains a lot of useful information about it, including the title, the slug, the ID, the author’s name, the image, and even the article’s body.
To extract the information from the JSON, you need to place this code before the event is triggered:
# Create set to track processed article IDs
processed_ids = set()
# Get response and set up response listener
response_received = asyncio.Event()
page.on(
“response”,
lambda response: check_json(
response, response_received, processed_ids))Now you can create a function to save the content in JSON format or CSV:
async def check_json(response, response_received, processed_ids):
“”“ Get data from HackerNoon JSON response “”“
url_response = (”https://hackernoon.com/_next/data/”)
if url_response in response.url:
try:
items = await response.json()
article_data = items[’pageProps’][’data’]
except Exception as e:
return
if article_data:
response_received.set()
# Extract article features based on example.json structure
try:
article_id = article_data.get(’id’)
# Check for duplicates using article ID
if article_id in processed_ids:
return
# Add to processed IDs set
processed_ids.add(article_id)
profile = article_data.get(’profile’, {})
# Extract stats data
stats = article_data.get(’stats’, {})
post_data = {
‘id’: article_id,
‘title’: article_data.get(’title’),
‘slug’: article_data.get(’slug’),
‘link’: “https://hackernoon.com/” + \
article_data.get(’slug’),
‘excerpt’: article_data.get(’excerpt’),
‘tldr’: article_data.get(’tldr’),
‘articleBody’: article_data.get(’articleBody’),
‘createdAt’: article_data.get(’createdAt’),
‘mainImage’: article_data.get(’mainImage’),
‘mainImageHeight’: article_data.get(’mainImageHeight’),
‘mainImageWidth’: article_data.get(’mainImageWidth’),
‘socialPreviewImage’: article_data.get(
‘socialPreviewImage’),
‘parentCategory’: article_data.get(’parentCategory’),
‘tags’: article_data.get(’tags’, []),
‘commentsCount’: article_data.get(’commentsCount’),
‘pageViews’: stats.get(’pageviews’),
‘arweave’: article_data.get(’arweave’),
‘author_name’: profile.get(’displayName’),
‘author_handle’: profile.get(’handle’),
‘author_avatar’: profile.get(’avatar’),
‘author_bio’: profile.get(’bio’),
‘author_isBrand’: profile.get(’isBrand’),
‘author_isTrusted’: profile.get(’isTrusted’)
}
# Save “post_data “data to JSON or CSV
except Exception as e:
print(”Error extracting article data: %s”, str(e)) Where do you see the URL response? You can find it in Headers under Network by inspecting the website’s page.
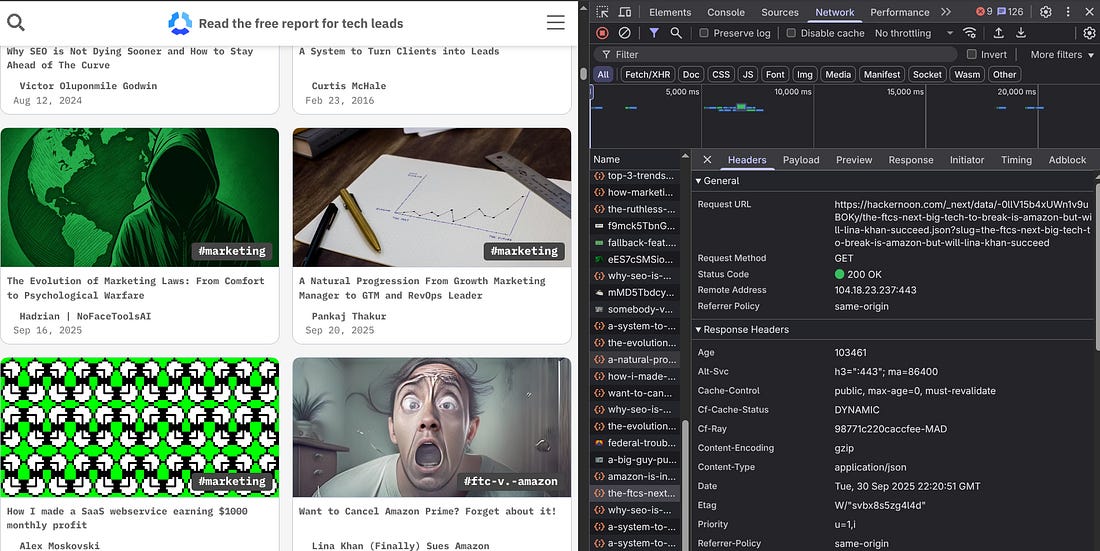
The Response tab under Network displays the JSON structure with all the fields you can scrape.
Now you know, next time, check this before engaging in intense HTML parsing, and note that the APIs can be triggered in different ways. Make sure to try buttons, filters, pagination, and scrolling.
This is how I built my Hackernoon Apify actor. You can try it yourself here.
3 - How to handle infinite scroll websites?
Many modern websites use infinite scroll to improve loading speed and improve the user experience. But they are definitely not loved by web scrapers.
Dealing with infinite scrolling can be challenging because websites tend to use different strategies to load their content. Scrolls can be located on different sides of the page. Some pages might not load content if you don’t move to the exact place on the page, others might require clicking to load more content, and so on.
The simplest way to scroll a page with Playwright is by using the wheel function:
n_scrolls = 10
for i in range(n_scrolls):
await page.mouse.wheel(0, 15000)
print(’scrolling’)
await page.wait_for_timeout(3000)
await page.mouse.wheel(0, -1500)
print(’move up’)
await page.wait_for_timeout(3000)The reason why I’m using a loop in the example above is that most pages with infinite scroll take some time to load the hidden content. Therefore, it may not work if you just scroll to the bottom of the page. With the loop, you can ensure the new data is loaded in each iteration.
While this strategy works, sometimes you can’t trigger the loading this way. The best approach is to move the cursor to the nearest element that triggers it. In the case of a news website, most likely the last visible element is an article/card, so that’s a good reference to scroll down to.
Let’s see how to implement it.
# scroll to the item
location = page.locator(”article”).last
await location.scroll_into_view_if_needed()With the two code snippets above, you should be able to handle most of the infinite scroll websites. Note that the more you scroll, the harder it gets to load, and your scraper can get very slow.
4 - How to target HTML elements accurately?
Sometimes using the page.locator() can be a real frustration. You try several classes, attributes, and text, and still the script prompts an error.
For those cases, my first approach is to target the main classes. Meaning that if you have an element with a lot of classes, start by tackling it with only one or two classes. This will make Playwright prompt an error similar to this:
playwright._impl._errors.Error: Locator.text_content: Error: strict mode violation: locator(”div.container-Qnseki”).first.locator(”a.pencraft.pc-reset”) resolved to 2 elements:
1) <a data-testid=”post-preview-title” href=”https://newsletter.theaiedge.io/p/adalflow-a-pytorch-like-framework” class=”pencraft pc-reset color-pub-primary-text-NyXPlw font-pub-headings-FE5byy clamp-y7pNm8 clamp-3-lxFDfR reset-IxiVJZ”>AdalFlow: A PyTorch-Like Framework to Auto-Optimi…</a> aka get_by_role(”link”, name=”AdalFlow: A PyTorch-Like”)
2) <a href=”https://newsletter.theaiedge.io/p/adalflow-a-pytorch-like-framework” class=”pencraft pc-reset color-primary-zABazT line-height-20-t4M0El font-text-qe4AeH size-15-Psle70 clamp-y7pNm8 clamp-2-kM02pu reset-IxiVJZ”>AI Agent frameworks are becoming just as importan…</a> aka get_by_role(”link”, name=”AI Agent frameworks are”)Since it doesn’t know which element you are referring to, it will kindly present you with multiple options.
From those options, you can use the recommended Playwright function to grab it, or use nth() with the right index.
If your selector still doesn’t work, switching to XPath inside the page.locator() function can often deliver more accurate results.
This is because XPath allows you to navigate the structure of the DOM directly.
Let’s take a look at this example.
Suppose you’re trying to target a button with a dynamic class name that changes on every page load. A CSS selector like this might fail:
button = page.locator(”.dynamic-button-class”)Instead, you can use an XPath expression that targets the element by its text content or position:
button = page.locator(”//button[contains(text(), ‘Submit’)]”)There are also Playwright built-in functions that mimic XPath:
button = page.locator(”button”).filter(has_text=”Submit”)You can either decide to learn the XPath expression language or explore more Playwright’s documentation. But avoid very long XPath expressions to optimize code readability.
5 - How to make proper proxy rotation?
Some of you are familiar with proxies and proxy rotation, but the real challenge arises when choosing the right proxy for your needs.
If anonymity and avoiding raising flags are your top priorities, residential proxies are the best option. However, if you are web scraping a website that doesn’t have strong blocking measures, you may want to prioritize speed, and datacenter proxies are a better solution.
I rely on proxy rotation when scraping more challenging websites, and IPRoyal’s trustworthy residential proxies have consistently met my needs.

IPRoyal proxies are also one of the cheapest in the market, with an excellent score on review platforms such as G2 and Trustpilot. You can create an account in a few seconds, without requiring too much personal information, and you can even pay with cryptocurrencies, if you don’t want to have your credit card attached to it.
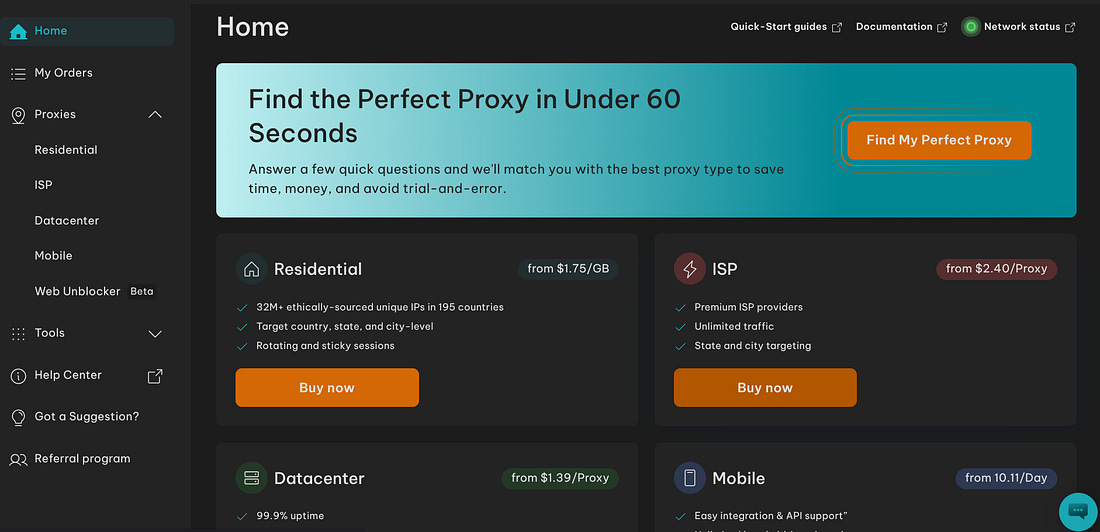
Once logged in, you have access to a user-friendly dashboard where you can select the best proxy option for your needs. If you don’t know what works best, you can answer a short survey to help you out.
If you decide to use residential proxies like me, you’ll see a page with your username, password, hostname, port, and several filters that allow you to customize your proxy’s location.
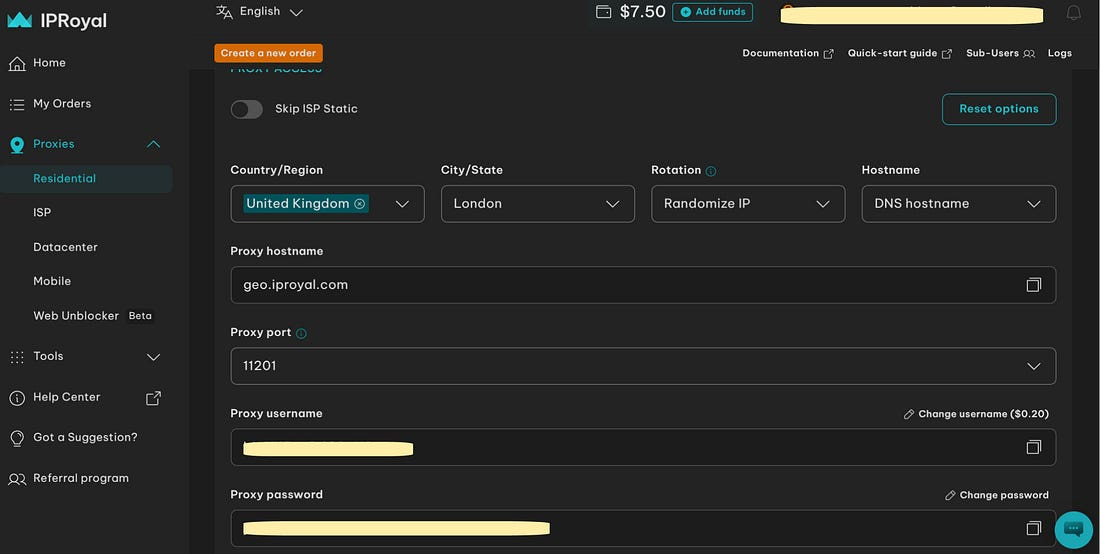
To implement proxy rotation, I select up to 7 different countries and cities, and I add them to a Python list in my script. It looks like this with Camoufox:
proxy_list = [
None, # No proxy first
“<key>_country-fr_city-toulouse”,
“<key>_country-es_city-valencia”,
“<key>_country-pt_city-lisbon”,
“<key>_country-es_city-madrid”,
“<key>_country-es_city-huelva”,
“<key>_country-es_city-sevilla”,
]
for proxy_element in proxy_list:
# Configure browser settings based on whether using proxy or not
browser_config = {
“os”: “windows”,
“humanize”: False, # Enable humanized cursor movement
“headless”: False, # Keep visible for debugging
“window”: (1280, 720), # Set window size
}
# Add proxy configuration if proxy_element is not None
if proxy_element is not None:
browser_config.update({
“geoip”: True,
“proxy”: {
“server”: “geo.iproyal.com:11201”,
“username”: “<my_username>”,
“password”: proxy_element
},
})
async with AsyncCamoufox(**browser_config) as browser:
# If page is accessed continue the script, if not try another proxy
While proxy rotation is beneficial to bypass anti-bot measures, it slows down your web scraper’s speed. Therefore, if speed is a top requirement, you can rent a Virtual Private Server (VPS), so you can run your script with multiple instances and at the same time, one for each proxy.
I use Contabo’s Cloud VPS 30 for only €12.5/month, which has 24 GB RAM (more than my laptop), 8 vCPU Cores, and 400 GB SSD. This plan is more than enough for most automation tasks, but feel free to have a look at the other VPS options available.

With my Contabo VPS, I can run concurrent web scrapers and schedule them using cron jobs at different times. This approach helps prevent my IP from being flagged while also conserving RAM for my primary tasks.
Need help with automation, AI, or data science? Let’s talk.
Conclusion
In this piece, we’ve covered the importance of Playwright headless browser for web scraping, and how it serves most of the web scraping tasks. Showing that you don’t need to learn multiple web scraping frameworks to build successful and performant crawlers.
Then we highlighted 5 different tips that vibe coding tools don’t tell you, but they make all the difference to turn you from a beginner to an advanced web scraping developer.
First, we discussed how to increase stealth and avoid being blocked by integrating Camoufox with Playwright.
Next, we looked at how intercepting HTTP responses before parsing HTML can save valuable time and help you capture hidden or critical data that might otherwise be missed.
We then examined how to handle infinite scroll pages efficiently using Playwright’s built-in functions, followed by strategies for optimizing data extraction with XPath or Playwright’s native selector capabilities.
Finally, we explored the differences between datacenter and residential proxies, highlighted the best options to start with, and explained how to integrate them effortlessly with Camoufox.
As demand for web scraping continues to grow, you can start applying these tips to land freelance projects on platforms like Upwork, build and monetize Apify actors for passive income, or simply create efficient crawlers for your own projects.
Perhaps this article will contribute to increasing even more the percentage of bots in internet traffic 🤖